Defending AI against adversarial attacks becomes more important every day as the world’s most popular and trusted services rely more and more machine learning models.
The two largest sellers of advertisers in the history of the world do not need to be convinced of the utility of machine learning. In 2018, a recruiting firm reported “80 percent of machine learning engineers with PhDs are scooped up by Google and Facebook.”
The integrity of AI systems is essential for companies who make tens of billions of dollars delivering ad impressions. And it is even more vital as adversarial attacks could be used to destroy reputations, influence global politics, and possibly even take down drones.
The problem with securing AI models
“Security Issues, Dangers and Implications of Smart Information Systems”, a new study published by the SHERPA consortium – an EU-funded project F-Secure joined in 2018 – explains why it’s so hard to secure AI models.
“Adversarial attacks against machine learning models are hard to defend against because there are very many ways for attackers to force models into producing incorrect outputs,” Section 4 on “Mitigations against adversarial attacks” explains. This helps explain why most models “in the wild” today are being trained “without regard to possible adversarial inputs.”
Models work as expected with expected inputs. Unfortunately, the number of unexpected inputs is… unexpected. And as the complexity of models increases, preparing models to withstand attacks becomes more and more difficult.
This task can be even more complex than the never-ending chore of identifying vulnerabilities in software because it “involves identifying inputs that cause the model to produce incorrect verdicts, such as false positives, false negatives, or incorrect policy decisions, and identifying whether confidential data can be extracted from the model.”
The report identifies 6 methods of mitigating against AI attacks.
Anticipate attacks with adversarial training
This method suggests anticipating attacks in the form of adversarial samples and including them in the model’s data set to reject.
“Unfortunately, there are plenty of other adversarial samples that can be created that still fool a model created in this way, and hence adversarial training itself only provides resilience against the simplest of attack methods,” the report notes.
Adversarial training resembles data augmentation, which is used, for instance, to improve AI photo recognition or image classifier models. “[B]y flipping, cropping, and adjusting the brightness of each input sample, and adding these to the training set” the model improves.
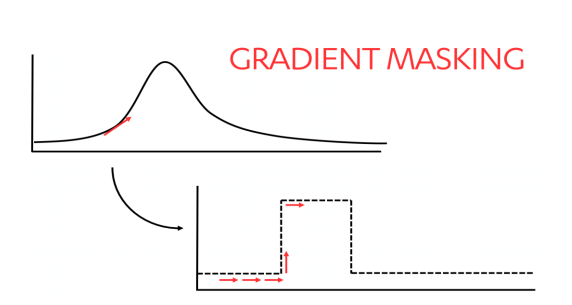
Confuse attackers with gradient masking
Attackers looking to get a sense of how a model’s makes decisions may try multiple inputs in an attempt to get a sense of a gradient in the results. This helps them see how the model works so they can replicate it and practice adversarial attacks against it.
“Gradient masking hampers this process by creating sharper decision boundaries as illustrated below…”
Protect your model by detecting and cleaning adversarial inputs
One way to protect your model is to put safeguards between it and the public. Detection and cleaning can remove attackers’ tricks and deliver raw data directly to the model.

Generative Adversarial Networks (GANs) help detect and cleanse inputs by training two different machine-learning models at the same time.
“One model, the generator, attempts to generate samples (e.g. images) from random noise. A second model, the discriminator, is fed both real samples and the samples created by the generator model,” the report notes. “The discriminator decides which samples are real, and which are fake. As training proceeds, the generator gets better at fooling the discriminator, while the discriminator gets better at figuring out which samples are real or fake.”
Safeguard user data with differential privacy
Differential privacy uses a general statistic technique prevent attackers from exposing the information in a statistical database.
One method of doing this requires the training a series of models against separate, unique portions of training data. Data is then fed into each model with a small amount of random noise. “The resulting values become ‘votes’, the highest of which becomes the output.”
OpenMinded—an open-source community—offers users access to the Syft project that allows simplified creation of multiple models to secure data via various methods, including differential privacy.
Preserve privacy for model training and inference using cryptographic techniques
Cryptographic methods are useful when multiple owners of data need to rely on each and don’t necessarily trust each other. It’s helpful both for the collaborative training a model or when one trained model produces outputs for multiple owners of data.
Multiple ways of encrypting data have been developed over the past five decades to provide owners a way of securing their data while gaining more utility from it, which can be used alone or in tandem to protect data privacy.
However, these techniques are only useful on a limited number of machine learning algorithms and can require a burdensome amount of computing power.
The human mind is the antidote to poisoning attacks
Web services have been dealing with poisoning attacks throughout this century, developing defenses required to preserve the reputation of their services.
The methods they’ve come up with fall generally within four categories — rate limiting, regression testing, anomaly detection, and human intervention.
Rate limiting strategies generally try to determine if a user is a human genuinely using a service or simulated human use designed to game the systems. Regression testing prevents attacks by testing new models against baseline standards to detect unexpected behavior. Anomaly detection methods can find suspicious usage by analyzing metadata including IP addressees using heuristic analysis to detect abnormal site usage.
But the most effective method of detecting AI abuse does not yet come from a machine—human intervention is required to create rules and directly moderate content.
Human beings bring human biases, which are more complicated than any model.
“However, as long as attackers are human, it will take other humans to think as creatively as the attackers in order to defend their systems from attack,” the report notes. “This fact will not change in the near future.
Categories