While machine learning applications can be exposed to common security threats at the hardware, application, and network level, they are also exposed to domain specific threats that are currently overlooked. Data poisoning is amongst the most serious threats they face. Data poisoning attacks compromise the integrity of machine learning models by injecting incorrect data in their training set. In this blogpost, we will outline common data poisoning attacks and their effect on machine learning models. We further explain and exemplify how these attacks can be algorithmically optimized and automatically run to achieve a greater impact. Based on our analysis, we provide insights on what type of machine learning models are more vulnerable to different types of poisoning attacks.
What is a data poisoning attack?
The performance of a machine learning model is highly dependent on the quality and quantity of data it is trained with. In order to train an accurate machine learning model, a large amount of training data is often required, and in order to obtain enough training data, practitioners may turn to potentially untrusted sources. This decrease in data quality, especially if that data wasn’t systematically checked to verify the correctness of its labels, opens the door to data poisoning attacks in which deliberately incorrectly labelled data can be inserted into a model’s training set with the goal of compromising the accuracy of that model.
A data poisoning attack aims to modify a training set such that the model trained using this dataset will make incorrect predictions. Data poisoning attacks aim to degrade the target model at training or retraining time, which happens frequently during. Poisoning attacks have a long-lasting effect because they compromise the integrity of the model and cause it to make consistent errors at runtime when making predictions. Once a model has been poisoned, recovering from the attack at a later date is a non-trivial procedure.

There are two different sub-goals for a data poisoning attack:
- Denial-of-service attack, where the goal is to decrease the performance of a target model as a whole. The predictive accuracy of the model will decrease for any input (or a majority of inputs) submitted to it.
- Backdoor/Trojan attack, where the goal is to decrease performance or force specific, incorrect predictions for an input or set of selected inputs. The predictive accuracy of the model will decrease only for inputs selected by the attacker. Accuracy is preserved for all other inputs.
Let’s take a simple example of a model designed to detect fraudulent orders placed on an e-commerce website. The model should be able to predict whether a placed order will be paid for (legitimate) or not (fraudulent) based on information about the given order. The training set for this model consists of details contained in historical orders placed on the website. In order to poison this training set, an attacker would pose as a user or users of the site and place orders. The attacker pays for some orders and doesn’t pay for others such that the predictive accuracy of the model is degraded when it is next trained. In the denial-of-service attack case, the goal is to cause the fraud detector to make incorrect decisions for any order placed by any user. In the backdoor/trojan attack case the goal is to cause the fraud detector algorithm to make incorrect decisions only for actual fraudulent orders placed by the attacker.
In order to execute a backdoor/trojan attack, an attacker places and pays for a number of orders using their own account which contains the same name, address, and other details as fraudulent orders they plan to place in the future. This order history will then be used to train the fraud detection algorithm. Later, the attacker can use the same account to place new orders and not pay for them. These fraudulent orders will be deemed legitimate by the model and will cause the merchant to lose money.
Poisoning attacks are usually realized using one of two methods:
- Data injection: by injecting new data in the training set, as illustrated above with the attacker creating new orders. This new data can be synthetic in nature.
- Label flipping: by changing labels of existing real data in the training set. This can be achieved by paying for orders with delay to change their status from fraudulent to legitimate in our example. In other cases, labels can be overwritten through customer support mechanisms.
The requirements to execute these two attacks differs. In order to perform data injection, an attacker needs only interact with the e-commerce site itself in order to generate synthetic data points and corresponding labels. In order to perform label flipping, an attacker must be able to change the labels of real data points that already exist in the training data. Although most attackers do not have the means to directly alter this data, in our fraud detection scenario, an attacker could use customer support mechanisms to submit feedback about “incorrectly” classified transactions in order to manipulate historical labels.
Data poisoning can be performed in an ad-hoc manner using either data injection or label flipping. When performing data injection, the attacker can make guesses about how the model provides predictions and thus create and inject new data that is expected to change these predictions. In our fraud detection example, the attacker pays for orders similar to ones they intend to place (but not pay for) later. What makes orders similar can only be assumed in this case and the expected impact of the injection on the decision of the model cannot be predicted. In label flipping, the attacker can modify the labels of randomly picked data points in the training set to achieve the same goal. Once again, while we know that by flipping the label of enough data points, we will degrade the accuracy of the model, the exact impact of this random attack cannot be anticipated.
Since machine learning models are built using standard algorithms that solve well-defined optimization problems, more effective data poisoning attacks can be mounted. Given some knowledge about the model and its training data, an attacker can generate synthetic training data points that will optimally degrade the accuracy of the model. The attacker can thereby optimize a poisoning attack by injecting the minimum number of data points required to reach their poisoning goal, whether it be denial-of-service or backdooring.
How to generate effective poisoning data points
To generate effective poisoning data points, we must start by considering how a dataset is used to train a machine learning model. Training a model involves optimizing an objective function that typically aims to minimize the (a distance) between predictions made by the model and the true labels in the training data. Through this process, the model learns to make correct predictions on the training data points. These correct predictions are expected to later generalize to new testing data (which is not part of the training set). Effective model training relies on the assumption that the training data is similar to, or comes from the same distribution as, the testing data that will be provided to the model at runtime. The goal of a poisoning attack is to challenge this assumption by modifying the training set such that it does not match the true distribution of the testing data . This is most often achieved by adding data with incorrect labels to the training set (using data injection or label flipping).
Knowing that the objective function used during model training aims to minimize the training error (prediction error on the training data), an attacker can generate new training data points with the goal to maximize the testing error (prediction error on the testing data). An optimal poisoning data point xp can be algorithmically generated for a given model by solving a bi-level optimization problem that (a) minimizes the training error while (b) maximizing the testing error on some test set chosen by the attacker. This means that the poisoning data point xp is generated such that when it is used together with a pre-defined training set to train a particular model, the resulting model will maximize the testing error on the test set chosen by the attacker. This problem can be solved iteratively using gradient ascent optimization for models trained using gradient-based algorithms such as Support Vector Machines (SVM), logistic regression, or (Deep) Neural Networks.
In order to optimize the generation of poisoned inputs, we need some knowledge of the model we’re trying to poison. Ideally, we need to know:
- the original training set in which we will inject poisoning data points
- the type of model to be poisoned (SVM, logistic regression, etc.)
- the hyperparameters of the model
- the loss function (objective function) used to compute the prediction error during training
This knowledge does not necessarily need to be exact – it can be approximated. The training set can be approximated with surrogate data from the same distribution. The training hyperparameters and loss function can also be approximated. Finally, the test set used to maximize the testing error is chosen by the attacker according to their goal. If the goal of the attack is denial-of-service, the test set needs to be large and representative of the true data distribution.
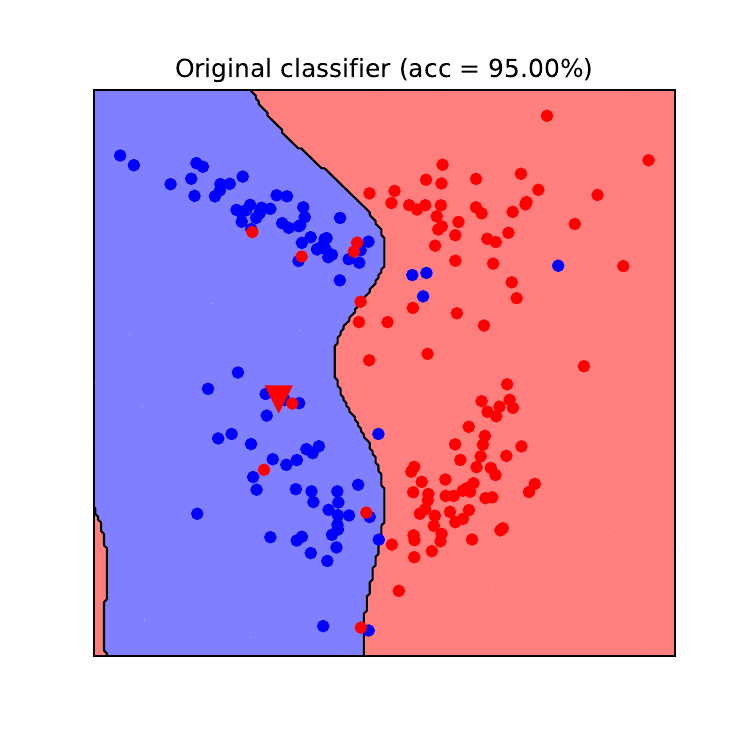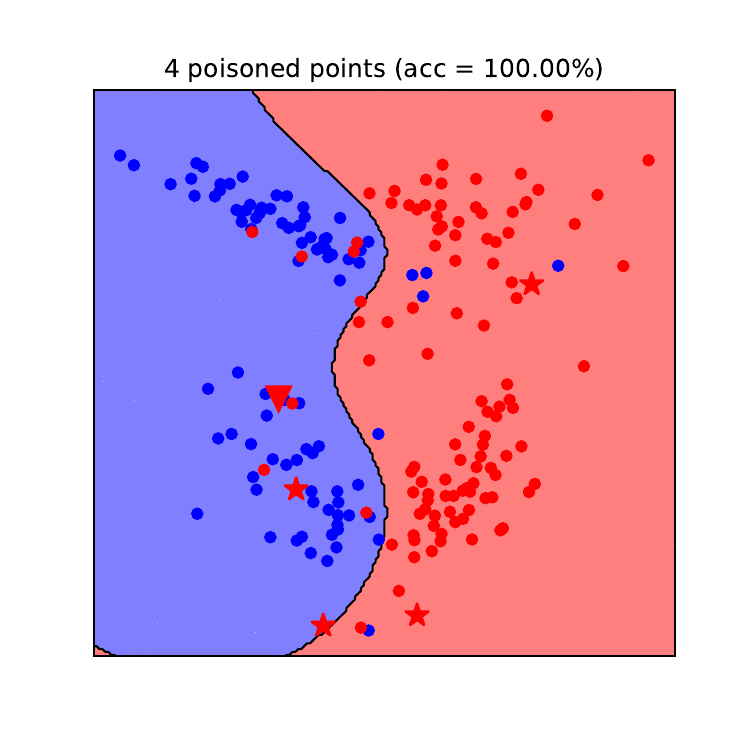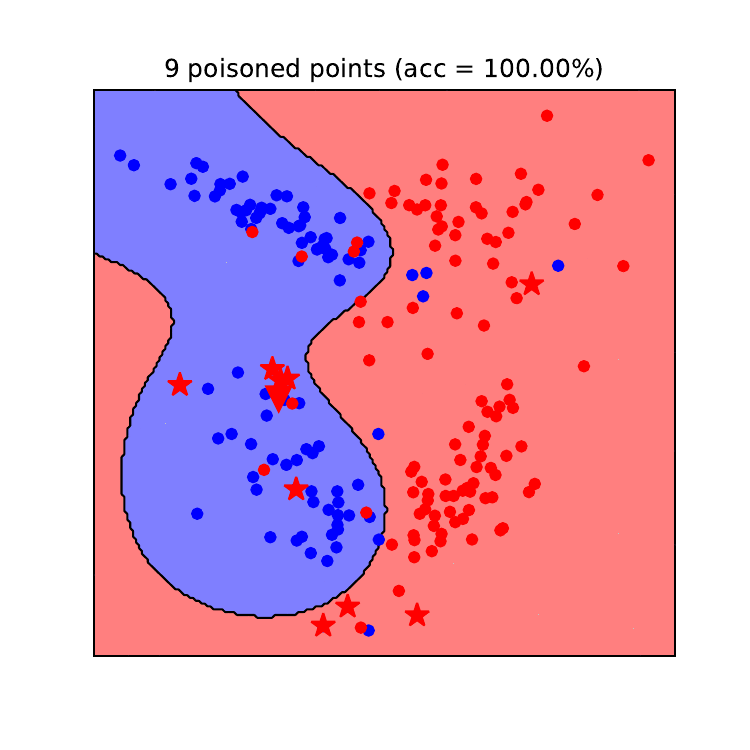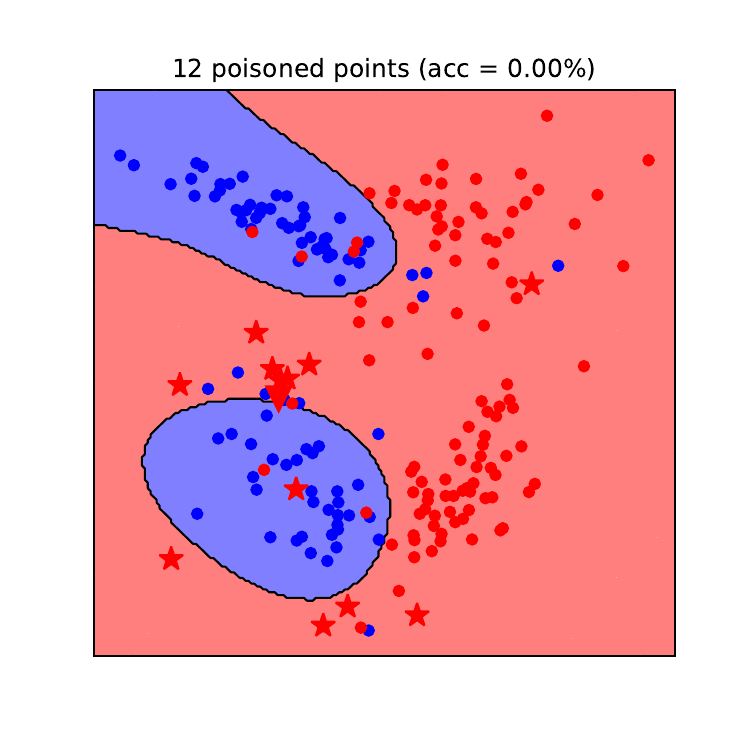
We now explain how to generate poisoned data points algorithmically by solving the bi-level optimization problem described above. In this example, we’ll use a training set composed of 200 data points, belonging to 2 different classes (blue and red), each represented by 2 features (for visualization purposes). We use this dataset to train an SVM model (with RBF kernel). Figure 2 illustrates the data points and model decision boundaries. This SVM model was evaluated using test data on which it reported 95% prediction accuracy.

In our first example, we’ll illustrate how to craft a denial-of-service poisoning attack against this model. We start by using the test set, trained SVM model, and training set to define our objective function. Our objective function computes the test error as a function of the poisoning data point to inject into the training set. Figure 3 shows the value of this function according to the coordinates of the data point that we inject into the training set. To generate a poisoned data point, we start by picking a random point in the space (black triangle) and assign it a random label/class (blue in this case). Then we iteratively change its coordinates (feature values) using gradient ascent optimization to maximize the value of our objective function, i.e., to maximize the test error. Observe that across several iterations, our initial poisoning data point moves (blue star) from a dark blue area (corresponding to a low value of the objective function) to a red area (corresponding to a high value of the objective function), i.e., this data point will maximize the prediction error on our test data.

Figure 3: Objective function for a DoS poisoning attack and generation of one poisoned data point
After a number of iterations, the algorithm defines the optimal values for the 2 features of our poisoned data point in order to degrade the accuracy of the SVM model to a maximum extent. Figures 4 and 5 show the location of the new data point with respect to the original training data and how the decision boundaries of the SVM model were affected by it. The new blue data point (indicated by a star) appears in the red class (mislabeled). This poisoned point is located close to a few other mislabeled blue points in the red area – an optimal location to modify the decision boundary of the SVM model. While we can see that this single data point has modified the decision boundary of the SVM model in its vicinity, it had little effect on the model’s accuracy. In order to generally lower the accuracy of the model, more poisoning data points need to be added.

This automated method of generating poisoning data can be applied to our previous fraud detection system example. The optimization would automatically define the optimal value for every feature that represents the poisoning order to be placed (name, address, items, amount, etc.). Then, as an attacker, we would place an order with these exact values and pay for it or not according to the label of the generated point. This method for generating poisoning data points optimizes the attack and makes its success more predictable.
How to run successful poisoning attacks
We have seen how to algorithmically generate a single poisoning data point by solving a bi-level optimization problem. In order to execute an attack that reaches our poisoning goals, we would need to generate several such data points using the same optimization problem. All of these poisoned data points must then be added to the original training set. As more poisoning points are added to the training set, the decision boundary of the poisoned model changes such that it will eventually provide the prediction errors targeted by the attacker. In figures 6 and 7, we illustrate this process on a logistic regression (LR) model (left) and an SVM model (right) using a denial-of-service poisoning attack.


![]()
As illustrated in figures 6 and 7, optimal poisoning points are different for different models trained using the same dataset:
- Logistic Regression builds a linear decision boundary that is sensitive to poisoning points located as far away as possible from their actual class: the left part of the space for the red class and the right part of the space for the blue class.
- SVM (with RBF kernel) builds a non-linear decision boundary that requires more scattered poisoning points in order to be modified.
This DoS attack is very effective against the logistic regression model. By increasing the number of poisoning points, the decision boundary is progressively tilted causing a drop in test accuracy from 91.5% to 53%. This DoS poisoning attack can be considered successful against the logistic regression model. On the other hand, while the decision boundary of the SVM model changes significantly as more poisoning points are added, its accuracy decreases from 95% to only 81.5%. SVM models with RBF kernel build more complex decision boundaries than logistic regression models and thus they can fit better poisoned data points with contradicting labels, while maintaining correct predictions on the genuine clean data points. In general, this means that complex models (models having a high capacity) are more resilient than simple models to DoS poisoning attacks, they require more poisoning data points to be compromised, and it is difficult to decrease their accuracy as a whole.
Figures 8 and 9 illustrate how the decision boundaries of a logistic regression model (left) and an SVM model (right) change during a backdoor poisoning attack. In this example, we chose a data point from the blue class (true label) that we wanted the model to predict as the red class (backdoored point). This point is depicted as a red triangle. We see that the backdoor poisoning attack required fewer poisoning data points to be successful (21 for logistic regression and 12 for SVM). For this attack, only poisoning data points from the target class (red) need to be generated and they are overall more grouped than for the DoS attack. In contrast to the DoS attack, the backdoor attack is more effective against the SVM model than against the logistic regression model. The same reason given above explains this effectiveness. Since SVM models with RBF kernel have a higher capacity than LR models, their decision boundary can better fit anomalies in the training set and create “exceptions” in their predictions. On the other hand, it requires more poisoned data points to move the linear decision boundary of the logistic regression model to fit these anomalies. The reason for this is that the prediction of the logistic regression model will need to contradict the label for a large number of clean data points in the training set, and therefore more poisoned data points are needed to tackle this issue.


Conclusions
Given some information about a machine learning model and its training data, data poisoning attacks can be executed automatically and efficiently. Optimal poisoning data points can be algorithmically generated by solving an optimization problem to reach both denial-of-service and backdoor goals. While the implementation of such poisoning attacks requires sufficient knowledge about machine learning and optimization techniques, several libraries are also already publicly available to generate poisoning data with limited effort and knowledge. Some examples include:
- SecML: https://secml.gitlab.io/
- Adlib: https://github.com/vu-aml/adlib
- AdvBox: https://github.com/advboxes/AdvBox
- AlfaSVMlib: http://pralab.diee.unica.it/en/ALFASVMLib
Data poisoning attacks can be performed against almost any machine learning model that sources third party data for training. This is the case in most deployment scenarios. Our fraud detection example illustrates the ease at which an attacker can pose as a legitimate customer in order to inject data or overwrite labels via customer service mechanisms.
The vulnerability of machine learning models to data poisoning attacks differ according to many parameters. One critical feature that impact this vulnerability is the capacity of a model: simple models with low capacity are more vulnerable to denial-of-service poisoning attacks while complex models are more vulnerable to backdoor poisoning attacks. This means that there is no silver bullet to generically protect models against data poisoning attacks by design. An additional line of defense must be added during the training process of a model in order to efficiently mitigate data poisoning attacks.
Besides data poisoning attacks, there also exist model poisoning attacks that can be performed in distributed training environments such as federated learning setups. In another blog post (https://labs.f-secure.com/blog/how-to-attack-distributed-machine-learning-via-online-training/), we demonstrate how to design such model poisoning attacks against a prototype anomaly detection system and provide recommendations to mitigate these attacks.
Acknowledgements
This research was conducted by Samuel Marchal (F-Secure Corporation) as part of F-Secure’s Project Blackfin which is a multi-year research effort with the goal of applying collective intelligence techniques to the cyber security domain.
Categories