Immer mehr Online-Services nutzen mittlerweile Machine-Learning-, bzw. KI-Systeme. Deswegen ist es so wichtig wie noch nie zuvor, diese adäquat gegen feindliche Angriffe zu schützen.
Vor allem Facebook und Google – die zwei größten Werbevermarkter der Geschichte – sind voll und ganz vom Einsatz und der Weiterentwicklung ihrer KI-Systeme überzeugt. 2018 veröffentlichte das amerikanische Unternehmen Talenya Informationen, nach denen schätzungsweise 80% aller Machine-Learning-Ingenieure mit Doktorgrad von jeweils einem der beiden Großunternehmen abgeworben werden.
Die Integrität von KI-Systemen ist dabei nicht zuletzt für Unternehmen, die mehrere Milliarden Dollar durch Ad-Impressions erzielen, von entscheidender Bedeutung. Gegnerische Attacken könnten nicht nur zu langfristigen Imageschäden, sondern auch zur Manipulation politischer Bewegungen – oder sogar zur feindlichen Übernahme von autonomen Drohnen führen.
Der Schutz von KI-Systemen ist eine besondere Herausforderung
„Security Issues, Dangers and Implications of Smart Information Systems“, so lautet der Titel einer neuen Studie des Konsortiums SHERPA – einem EU-finanzierten Forschungsprojekt, bei dem F-Secure seit 2018 Mitglied ist. Sie zeigt auf, warum der vollumfängliche Schutz von KI-Systemen gegen feindliche Angriffe noch immer eine große Herausforderung darstellt.
KI- oder Machine-Learning-Modelle sind besonders schwierig gegen Angriffe von außen abzusichern, da sie den Angreifern häufig zahlreiche Möglichkeiten bieten, die sie zur Erzeugung von manipulierten Ergebnissen bewegen. Dies erklärt auch, warum die meisten Modelle heutzutage ohne Rücksicht auf mögliche Fehleingaben trainiert werden: KI-Systeme arbeiten wie erwartet, sofern sie mit erwartbarem Input gefüttert werden.
Leider ist der Anteil von unerwartetem Input häufig auch unerwartet hoch. Und je komplexer diese Systeme in Zukunft werden, desto schwieriger wird es, sie auf etwaige Attacken vorzubereiten.
Die Absicherung von künstlich intelligenten Systemen kann schnell noch komplexer werden als die eh schon schier unendliche Suche nach Sicherheitslücken in Softwares ohne Einsatz von KI. Nun müssen nämlich auch diejenigen Eingaben gefunden und analysiert werden, die schlussendlich zur Fehlentscheidung des Algorithmus geführt haben. Außerdem müssen Sicherheitsbeauftragte abwägen, ob zum Zweck der Absicherung dieser Systeme auch vertrauliche Daten aus ihnen extrahiert werden dürfen.
Der Bericht beschreibt sechs Methoden zur Abwehr von KI-Angriffen.
Gegnerische Angriffe durch entsprechendes Training antizipieren
Diese Methode sieht vor, dass schädliche Eingaben bereits während der Programmierung der KI-Funktion antizipiert werden. Das System soll darauf trainiert werden, entsprechende Anfragen abzulehnen.
Leider existieren jedoch auch dann noch immer unzählige weitere Eingabeoptionen, die ein Angreifer stattdessen nutzen kann und die das System am Ende auf eine ähnliche Weise zu täuschen vermögen. Außerdem – so merkt der SHERPA-Bericht an – schützt diese Methode wirklich nur vor der simpelsten Art von Angriffen.
Dieses antizipierende Training auf mögliche gegnerische Attacken ähnelt der sogenannten „Data Augmentation“, die zum Beispiel zur Verbesserung von Fotoerkennungssoftware oder zur Bildklassifizierung verwendet wird und die das Trainingsset erweitert, indem einzelne Bilddateien mehrfach und auf verschiedenste Art gedreht, beschnitten und in ihrer Helligkeit verändert werden.
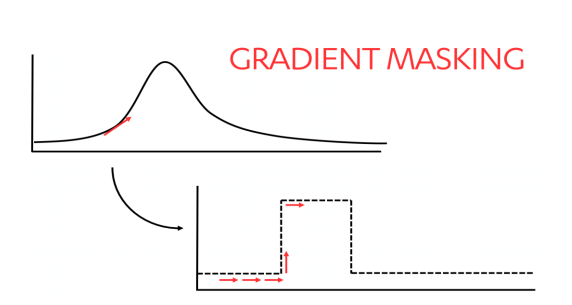
Angreifer durch “Gradient Masking” verwirren
Wenn Angreifer verstehen möchten, auf welche Weise KI-Systeme ihre Entscheidungen treffen, probieren sie an diesen zunächst verschiedene und jeweils leicht abgewandelte Eingaben aus. Aus der Reaktion der Algorithmen auf diese Eingaben leiten sie dann mehr oder weniger genau deren Funktionsweise ab. Angreifer können aus diesen Erkenntnissen anschließend eine Kopie des jeweils verwendeten Modells erstellen und in einer Testumgebung verschiedenste Angriffsszenarien konzipieren und testen.
“Gradient Masking” behindert diesen Prozess, indem es schärfere Entscheidungsgrenzen für die KI festlegt, wie im Folgenden dargestellt:
Feindliche Eingaben erkennen und beseitigen
Eine weitere Möglichkeit, ein KI-Modell vor Angriffen von außen zu schützen, sind zwischengeschaltete Schutzmaßnahmen. Durch die aktive Erkennung und Bereinigung von schädlichen Eingaben können außerdem wichtige Rohdaten zu den einzelnen Angriffen gewonnen werden.

Generative Adversarial Networks (GANs) sorgen für die Erkennung und Beseitigung von manipulativen Eingaben, indem zwei verschiedene Machine-Learning-Modelle gleichzeitig darauf trainiert werden.
Ein Generatorsystem („Generator“) versucht dabei gefälschte Eingaben (z. B. Bilder) aus einem zufälligen Rauschen zu erzeugen. Ein weiteres Modell – der sogenannte „Discriminator“ – bekommt sowohl echte als auch die gefälschten Eingaben des Generators eingespeist. Der Discriminator entscheidet anschließend, welche Samples echt und welche gefälscht sind. Während das Training voranschreitet, versucht der Generator, den Discriminator auf immer ausgeklügeltere Weise zu täuschen. Aber auch der Discriminator wird immer besser in der Identifizierung von richtigen und falschen Eingaben und lässt sich anschließend nicht mehr so einfach hintergehen.
Schutz der Nutzerdaten durch „Differential Privacy“
„Differential Privacy“ hindert Angreifer durch statistische Methoden daran, Informationen in einer statistischen Datenbank offen zulegen, und erfordert KI-Systeme auf unterschiedliche Eingaben zu trainieren. Diese Eingaben werden dann mit einem geringen Anteil von zufälligem Rauschen wieder in die jeweiligen Systeme gespeist. Die sich aus den Analysen der KI-Systeme ergebenden Werte werden anschließend in „Votes“ umgewandelt, von denen der höchste zum endgültigen Output wird.
Die Open Source Community OpenMind bietet ihren Nutzern Zugriff auf das sogenannte Syft-Projekt. Dieses ermöglicht die unkomplizierte Erstellung verschiedenster KI-Modelle, um Daten auf unterschiedlichste Art und Weisen abzusichern. Auch „Differential Privacy“ wird unterstützt.
Inferenz und Datenschutz durch Verschlüsselungstechniken bewahren
Kryptografische Methoden sind beim Einsatz von KI-Systemen vor allem dann nützlich, wenn sich mehrere Eigentümer von Daten auf einander verlassen müssen, sich dabei gegenseitig jedoch nicht unbedingt vertrauen. Sie eignen sich sowohl für das gemeinschaftliche Training eines KI-Systems als auch dann, wenn das System getrennte Daten an verschiedene Eigentümer ausgeben muss.
Innerhalb der letzten Jahrzehnte wurden unterschiedlichste Methoden zum Verschlüsseln von Daten entwickelt, die gleichzeitig einen wichtigen Trainingsnutzen für die KI bieten. Diese Verschlüsselungsmethoden können alleinstehend oder zusammenwirkend zur Wahrung des Datenschutzes eingesetzt werden.
Sie sind jedoch häufig nur für eine begrenzte Anzahl von Machine-Learning-Algorithmen nützlich und können unter Umständen eine ganze Menge an Rechenleistung erfordern.
Der menschliche Verstand ist das Gegengift für Poisoning-Attacken
Viele Onlinedienste mussten sich in den letzten Jahren bereits mit Poisoning-Attacken auf ihre KI-Systeme auseinandersetzen und entsprechende Schutzmechanismen entwickeln, um das Image ihres Angebots zu bewahren.
Diese Schutzmechanismen lassen sich im Allgemeinen in vier Kategorien einteilen: Durchsatzratenbegrenzung, Regressionstests, Anomalieerkennung und menschliches Eingreifen.
Techniken zur Durchsatzratenbegrenzung versuchen zu bestimmen, ob ein Nutzer tatsächlich ein Mensch ist oder ob es sich um einen Bot handelt, der zum Überlisten des Systems eingesetzt wird. Regressionstests verhindern Angriffe, indem sie neuartige Eingaben grundlegenden Standards gegenüberstellen, um daraus möglicherweise ein unerwartetes Verhalten abzuleiten. Anomalieerkennungsmethoden können verdächtige Nutzungstypen feststellen, indem sie die Metadaten der Nutzer (einschließlich IP-Adressen) mithilfe einer heuristischen Analyse auswerten, um daraus Abweichungen zu erkennen.
Die effektivste Methode zur Erkennung von KI-Missbrauch stammt jedoch noch nicht von einer Maschine, sondern kommt vom Menschen selbst. Erst durch menschliches Eingreifen können neue Regeln erstellt und Inhalte entsprechend moderiert werden.
Menschen bringen immer auch rein menschliche Vorbehalte mit sich, die komplexer sind als jedes KI-Modell.
Solange Angriffe von Menschen kommen, solange müssen auch andere Menschen so kreativ denken wie die Angreifer selbst, um ihre Systeme vor böswilligen Attacken zu schützen. Dieser Sachverhalt wird sich auch in naher Zukunft nicht ändern.

Kategorien