世界で最もよく知られ信頼されているサービスの機械学習モデルへの依存が進むにつれて、AIを機械学習に対する敵対的攻撃から防御することが一層重要になっています。
世界最大級の2つの広告販売会社は、機械学習の有用性については確信するまでもありません。人材スカウト会社の報告(英語)によると、2018年には、「博士号を持つ機械学習エンジニアの80%がグーグルとフェイスブックによってすくい取られました。」
広告を表示して何百億ドルもの利益を挙げる会社にとって、AIシステムの完全性は絶対に必要です。機械学習に対する敵対的攻撃は、評価を損ねたり、国際政治に影響を与えたり、また、場合によってはドローンを悪用するために利用される可能性もあるため、AIシステムの完全性はより重要なものとなっています。
AIモデルを守る上での問題
EUが出資しエフセキュアが2018年から参加しているプロジェクトであるSHERPAコンソーシアムが発表した新しい研究、「スマート情報システムのセキュリティ問題、危険性および影響」には、AIモデルの保護がなぜ非常に困難であるのかが説明されています。
この発表のセクション4「敵対的攻撃防止対策」では、「機械学習モデルに対する敵対的攻撃は、学習モデルに誤った出力を生成させる方法が非常に多くあるため、防御が困難である」と述べています。これは、現在「使用されている」機械学習モデルのほとんどが、「敵対的入力が行われる可能性を考慮せずに」訓練が行われていることをよく示しています。
機械学習モデルは、予期される入力によって予測通りに機能します。しかし残念ながら、予期しない入力の数は予期できません。学習モデルがより複雑になると、モデルが攻撃に対抗できるようにすることは一層困難になります。
この作業は、「誤検出や検出漏れ、またはモデルが不適切なポリシーの設定を引き起こす入力の発見や、モデルから機密データを抽出できるかを確認する作業を伴う」ため、ソフトウェアの脆弱性を発見する際限のない作業よりもさらに複雑な場合があります。
報告書では、AI攻撃を軽減する6つの方法を明らかにしています。
敵対的訓練によって攻撃を予測
この方法は、敵対的サンプルで攻撃を予測し、サンプルをモデルのデータに含めることによって攻撃を撃退するものです。

「しかし残念ながら、このようにして作成されたモデルをだます敵対的サンプルは他にも多数あるため、敵対的訓練そのものは最も単純な攻撃方法に対する対抗手段にしかなりません。」と報告書では指摘しています。
敵対的訓練は、たとえばAIの写真認識または画像分類器モデルの向上などに使用されるデータの増強に類似しています。「各入力サンプルの明度を反転、低減、調整し、それらを訓練セットに追加することによって」モデルは向上します。
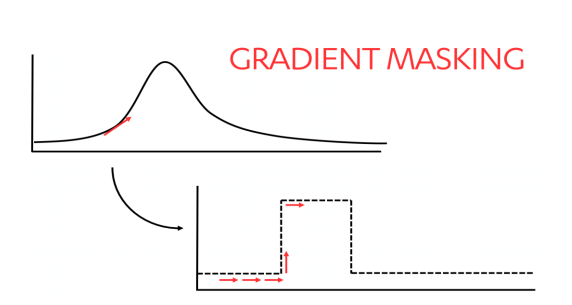
勾配マスキングによって攻撃者を混乱
学習モデルがどのように決定を行っているかを理解しようしている攻撃者は、結果の中の勾配の意味を知ろうとして複数の入力を試みる可能性があります。これによってモデルがどのように機能しているかが分かるため、攻撃者はモデルを複製し、それに対して敵対的攻撃を実行できるようになります。
「以下に示すように、勾配マスキングは、より明確な決定境界を作成することによって攻撃者による入力を阻止します。」
敵対的入力を検知、除去してモデルを保護
学習モデルを保護する方法の一つは、モデルと人々との間に防御措置を講ずることです。検知、除去するころによって攻撃者の策略を排除し、生データを直接モデルに配信できます。
敵対的生成ネットワーク(GANs)は、2つの異なる機械学習モデルを同時に訓練することによって入力を検知、除去できるようにします。
報告書では、次のように解説しています。「生成者である一つのモデルが、ランダムなノイズからサンプル(例えば画像)を生成しようとします。識別者である2番目のモデルには本物のサンプルと生成モデルが作成したサンプルが入力されます」。「識別者はどちらのサンプルが本物でどちらが偽物かを決定します。訓練が進むと、生成者は識別者をだますことが上手くなりますが、識別者も本物と偽物を区別することが上手くなります。」
ユーザーのデータを差分プライバシーで保護
差分プライバシーは、一般的統計手法を用いて統計データベース内の情報が攻撃者によって公開されないようにします。
これを実行する方法の一つは、訓練データの個別で固有の部分に対して一連のモデルを訓練することです。データは次に少量のランダムなノイズとともに各モデルに入力されます。「入力結果の数値によって『決定』され、最も高い数値が出力されます。」
オープンソースのコミュニティであるOpenMinded(英語)では、ユーザーがSyftプロジェクトにアクセスし、データを保護するために差分プライバシーを含むさまざまな方法で複数のモデルを簡単に作成することができます。
暗号技術を用いて学習モデルの訓練や推定におけるプライバシーを遵守
暗号化方式は、複数のデータ所有者がお互いに依存する必要があるが必ずしも互いを信頼していない場合に便利です。モデルの共同訓練や、訓練した1つのモデルが複数のデータ所有者に対して出力する場合に便利です。
この50年間にデータを暗号化するさまざまな方法が開発され、データ所有者は、単独または連携した暗号化によってデータを保護できるようになるとともに、データをより有効に利用できるようになりました。
しかし、これらの技術を利用できる機械学習のアルゴリズムの数は限られており、計算には非常に手間がかかります。
人間の心は有害な攻撃に対する解毒剤
ウェブサービスは、今世紀と通じて有害な攻撃に対処し、サービスに対する評価を維持するために必要な防衛策を講じてきました。
考案された方法は、レート制限、リグレッションテスト、異常検出、人による加入の大きく4つに区分できます。
レート制限方法は通常、ユーザーが本当にサービスを利用している人間か、システムを操るための偽の人間かを判定しようとします。リグレッションテストは、新しいモデルを基本となる基準に対してテストし、予期しない振る舞いを検知します。異常検出方法は、ヒューリスティックな解析によってIPアドレス等のメタデータを解析することによってサービスの不審な利用を発見し、サイトの異常な利用を検出します。
しかし、AIの不正使用を検出する最も効果的な方法は機械によるものではありません。ルールを作成しコンテンツを直接管理するには人間による介入が必要です。
人間には他のいかなるモデルよりも複雑な先入観があります。
報告では次のように述べています。「しかし、攻撃者が人間である以上、システムを攻撃から守るには攻撃者と同じくらいに創造的に考える別の人間が必要になります。」これは今後も変わらないでしょう。