This is the fourth and final article in a series of four articles on the work we’ve been doing for the European Union’s Horizon 2020 project codenamed SHERPA. Each of the articles in this series contain excerpts from a publication entitled “Security Issues, Dangers And Implications Of Smart Systems”. For more information about the project, the publication itself, and this series of articles, check out the intro post here.
This article explores currently proposed methods for hardening machine learning systems against adversarial attacks.
Introduction
Most machine learning models ‘in the wild’ at present are trained without regard to possible adversarial inputs. As noted in the previous article in this series, the methods required to attack machine learning models are fairly straightforward, and work in a multitude of scenarios. Research into mitigation against commonly proposed attacks on machine learning models has proceeded hand-in-hand with studies on performing those attacks. Naturally, a lot more thinking has gone into understanding how to defend systems that are under attack on a daily basis compared to those being attacked in purely academic settings.
Adversarial attacks against machine learning models are hard to defend against because there are very many ways for attackers to force models into producing incorrect outputs. Most of the time, machine learning models work very well on a small subset of all possible inputs they might encounter. As models become more complex, and must partition between more possible inputs, hardening against potential attacks becomes more difficult. Unfortunately, most of the mitigations that have been proposed to date are not adaptive, and they are only able to close a small subset of all potential vulnerabilities.
From the implementation point of view, a machine learning model itself can be prone to the types of bugs attackers leverage in order to gain system access (such as buffer overflows), just like any other computer program. However, the task of hardening a machine learning model extends beyond the task of hardening a traditionally developed application. Penetration testing processes (such as fuzzing – the technique of providing invalid, unexpected, or random inputs into a computer program) and thorough code reviewing are commonly used to identify vulnerabilities in traditionally developed applications. The process of hardening a machine learning model additionally involves identifying inputs that cause the model to produce incorrect verdicts, such as false positives, false negatives, or incorrect policy decisions, and identifying whether confidential data can be extracted from the model.
Adversarial training
One proposed method for mitigating adversarial attacks is to create adversarial samples and include them in the training set. This approach allows a model to be trained to withstand common adversarial sample creation techniques. Unfortunately, there are plenty of other adversarial samples that can be created that still fool a model created in this way, and hence adversarial training itself only provides resilience against the simplest of attack methods.
Adversarial training is a natural accompaniment to data augmentation – the process of modifying samples in a training set in order to improve the generalization and robustness of a model. For instance, when training an image classifier, data augmentation is achieved by flipping, cropping, and adjusting the brightness of each input sample, and adding these to the training set.
Gradient masking
Gradient masking is a method designed to create models that are resistant to white box probing for decision boundaries, typically in neural network-based models. Mapping a target model’s decision boundaries involves crafting new input samples based on the gradient observed across outputs from previously crafted samples. Gradient masking hampers this process by creating sharper decision boundaries as illustrated below.
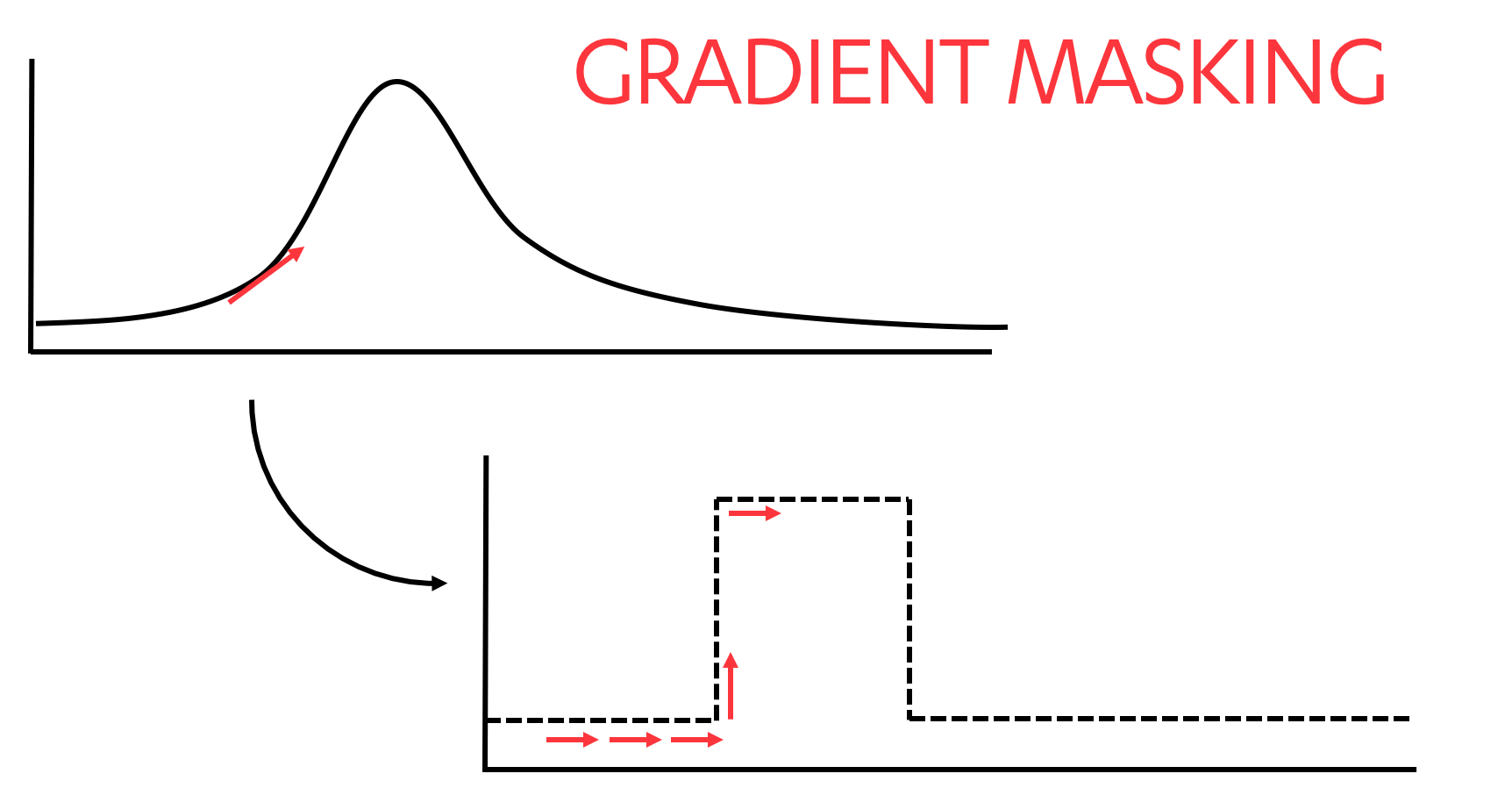
Commonly referenced techniques for masking gradients include defensive distillation and defensive dropout. Defensive distillation is a process whereby a second model is created from the output of one or more initially trained models. The second model is trained on modified Softmax output values of the first model (as opposed to the hard labels that were used to train the initial model). Dropout – the process of randomly disabling a portion of the model’s cells – is a method commonly used during model training as a regularization technique to encourage models to generalize better. Defensive dropout applies the dropout technique during the model inference phase. Stochastic activation pruning is another gradient masking technique similar to defensive dropout. We note that gradient masking techniques do not make a model resistant to adversarial samples in general.

Dropout in neural networks. Source: https://medium.com/@amarbudhiraja/https-medium-com-amarbudhiraja-learning-less-to-learn-better-dropout-in-deep-machine-learning-74334da4bfc5
Detecting and cleaning adversarial inputs
A machine learning model can be shielded from adversarial inputs by placing safeguard mechanisms between the public interface to the model’s input and the model itself. These mechanisms detect and clean adversarial perturbations in the raw input, prior to it reaching the model. Detection and cleaning can be performed in separate steps, or as part of a single step.

Generative Adversarial Networks (GANs) are a type of machine learning model designed to generate images, or other types of data. Training a GAN involves training two neural network models simultaneously. One model, the generator, attempts to generate samples (e.g. images) from random noise. A second model, the discriminator, is fed both real samples and the samples created by the generator model. The discriminator decides which samples are real, and which are fake. As training proceeds, the generator gets better at fooling the discriminator, while the discriminator gets better at figuring out which samples are real or fake. At the end of training, the generator model will be able to accurately generate samples (for instance, convincing high-resolution photographs), and the trained discriminator model will be able to accurately detect the difference between real and fake inputs. Thus, discriminator models can be used to detect adversarial perturbations.

Suggested cleaning methods include using the output of the GAN generator model as the input to the target model, using a separate mechanism to generate an image similar to the original input, or modifying the input image to remove perturbations.
This two- (or three-) step process can actually be accomplished using a single step. Introspective neural networks are classifiers that contain built-in discriminator and generator components as part of a single end-to-end model. Trained models can be used both as a generator, and a classifier, and are resistant to adversarial inputs due to the presence of the discriminator component.
Another proposed solution, replaces the ‘detect and clean’ approach with a simple sanitization step that normalizes inputs prior to their reaching the safeguarded model.
Differential privacy
Differential privacy is a general statistical technique that aims to provide means to maximize the accuracy of query responses from statistical databases while measuring (and thereby hopefully minimizing) the privacy impact on individuals whose information is in the database. It is one proposed method for mitigating against confidentiality attacks.
One method for implementing differential privacy with machine learning models is to train a series of models against separate, unique portions of training data. At inference time, the input data is fed into each of the trained models, and a small amount of random noise is added to each model’s output. The resulting values become ‘votes’, the highest of which becomes the output. A detailed description of differential privacy, and why it works, can be found here.

Differential privacy is a hot topic at the moment, and online services such as OpenMined have sprung up to facilitate the generation of privacy-protected models based on this technique.
Cryptographic techniques for privacy-preserving model training and inference
Cryptographic techniques are a natural choice for ensuring confidentiality and integrity, and there is a growing interest in applying those techniques to data and model protection in machine learning. Several cryptographic methods have been successfully utilized, individually and in combination, for scenarios where data and model owners are different entities which do not trust each other. The two main use cases can be Informally described as follows:
- model training, when multiple data owners either provide their data to a single party constructing a model or exchange parts of their data for learning a model in a distributed fashion;
- inference, when a trained model is used for processing inputs provided by data owners to produce an output, such as a classification decision or a prediction.
Confidentiality of data is clearly a concern in both cases, and, in addition, model stealing concerns often need to be addressed in scenario (ii). Conceptually, both (i) and (ii) can be considered instances of the secure multi-party computation problem (secure MPC), where a number of parties want to jointly compute a function over their inputs while keeping the inputs private. This problem has been extensively studied in the cryptographic community since the 1970s, and a number of protocols have recently found application in machine learning scenarios. We will now introduce several popular approaches.
Homomorphic encryption makes it possible to compute functions on encrypted data. This enables data owners to encrypt their data and send the encrypted inputs to a model owner and, possibly, other data owners. The model is then applied to the encrypted inputs (or, more generally, a desired function is computed on the encrypted inputs), and the result is communicated to appropriate parties, which can decrypt it and obtain desired information, for example, the model output in scenario (ii). So-called fully homomorphic encryption enables parties to compute a broad class of functions, covering essentially all cases of practical interest. However, all of the currently developed fully homomorphic encryption techniques are very computationally expensive and their use is limited. A more practical alternative is so-called semi-homomorphic encryption methods. While those are suitable only for computing narrower classes of functions, they are utilized, usually in combination with other techniques, in several machine learning applications, for example, in collaborative filtering.
Secret sharing-based approaches can be used to distribute computation among a set of non-colluding servers, which operate on cryptographically derived shares of data owner inputs (thus, having no information about the actual inputs) and generate partial results. Such partial results can then be combined by another party to obtain the final result. One example of this approach is a privacy-preserving system for performing Principle Component Analysis developed on top of the ShareMind technology by Cybernetica.
Garbled circuit protocols, based on the oblivious transfer technique, are used for secure two-party computation of functions presented as Boolean circuits and can be employed in scenario (ii). In such protocols, one party prepares a garbled (encrypted) version of a circuit that implements the function to be computed, garbles their own input, and collaborates with the other party to garble their input in a privacy-preserving manner. The other party uses then the garbled circuit and inputs for computing a garbled output and collaborates with the first party to derive the actual function output. Garbling methods are often used for privacy-preserving machine learning in combination with semi-homomorphic encryption.
There are several noteworthy limitations of the use of cryptographic techniques in machine-learning-based systems. In particular, most of such techniques are applicable only to certain (a small number of) machine learning algorithms and are computationally expensive. Besides, one has to carefully check assumptions, which the security guarantees of cryptographic methods are based on. For example, the non-collusion assumption in secret sharing-based approaches may or may not be plausible in specific applications.
Despite the limitations and challenges, a number of platforms and tools for privacy-preserving machine learning have been developed (such as Faster CryptoNets and Gazelle), and this remains a domain of active theoretical and applied research.
Defending against poisoning attacks
Poisoning attacks have been popular for many years. Some of the largest tech companies in the world put a great deal of effort into building defences against these attacks. Mitigation strategies against poisoning attacks can be grouped into four categories – rate limiting, regression testing, anomaly detection, and human intervention.
Rate limiting strategies attempt to limit the influence entities or processes have over the model or algorithm. Numerous mechanisms exist to do this. The defender can:
- Take steps to ensure that a small group of entities, including IPs or users, cannot account for a large fraction of the model training data.
- Put mechanisms in place to prevent over-weighting of false positives and false negatives reported by users.
- Limit the number of examples that each user can contribute, for instance, by the use of decaying weights.
- Slow potential attacks or suspicious activity via mechanisms such as CAPTCHA.
- Give higher weighting to registered, or ’high-quality’ users.
- Calculate validity scores for registered accounts based on relevant metrics such as activity patterns, connecting IP addresses, behaviour, and so on.
In order to curb poisoning attacks, regression testing is a useful practice. It is less likely that attacks might slip through the cracks if newly trained models are checked against baseline standards. Good regression testing practices include:
- Compare each newly trained model to the previous one to estimate how much has changed. Alert on larger than expected changes and inspect the training data if an alert happens.
- Use A/B testing to compare the output of a previous and new model on real-world inputs.
- Implement continuous testing against a dataset containing attacks and normal behavioural data that a model must accurately handle.
Anomaly detection methods can be useful in finding suspicious usage patterns. Maintainers of social networks and other online services prone to poisoning attacks should be able to implement fairly intelligent anomaly detection methods using metadata they have available. These can include:
- IP-based anomaly detection.
- Heuristic analyses (look for ‘unpopular’ items that suddenly have many co-visitations with other items).
- Analysis of temporal dynamics of visits and co-visits.
- Implementation of one or more of the many proposed graph-based Sybil attack detection methods.
Although data analysis techniques and machine learning methods can be used to detect some suspicious activity, understanding how attacks are being carried out, and finding edge cases that are being abused is an activity most suited to humans. Much of the manual work required to defend against poisoning attacks relies on the creation of hand-written rules, and human moderation.
Whenever humans are involved in moderation activities and the processing of data, ethical considerations apply. Often, companies are faced with decisions such as what data a human moderator can work with, how good or bad content is defined, how to write rules that automatically filter ‘bad’ content, and how to handle feedback. These issues often force companies to tread a fine line between political beliefs and definitions of free speech. However, as long as attackers are human, it will take other humans to think as creatively as the attackers in order to defend their systems from attack. This fact will not change in the near future.
Conclusions
Adversarial attacks against machine learning models are hard to defend against because there are very many ways for attackers to force models into producing incorrect outputs. Complex problems can sometimes only be solved with the application of sophisticated machine learning models. However, such models are difficult to harden against attack. Research into mitigations against commonly proposed attacks has proceeded hand-in-hand with studies on performing those attacks.
It is important to bear in mind that methods of defending machine-learning-based systems against attacks and mitigating malicious use of machine learning may lead to serious ethical issues. For instance, tight security monitoring may negatively affect users’ privacy and certain security response activities may weaken their autonomy.
In an effort to remain competitive, companies or organizations may forgo ethical principles, ignore safety concerns, or abandon robustness guidelines in order to push the boundaries of their work, or to ship a product ahead of a competitor. This trend towards low quality, fast time-to-market is already prevalent in the Internet of Things industry, and is considered highly problematic by most cyber security practitioners. Similar recklessness in the AI space could be equally negatively impactful, especially when we consider the fact that our knowledge of how to mitigate adversarial attacks against machine learning models is so young. It took many years, if not decades, for traditional software development process to include practises such as threat modelling and fuzz testing. We would hope that similar practises are introduced into the AI development process much more quickly.
This concludes our series of articles. As mentioned, if you’re interested in reading the entire document, you can find it from here.
Categories