Artificial Intelligence (AI) verdedigen tegen mensen. Is dat nodig?
Jazeker! De populairste en meest vertrouwde diensten ter wereld maken steeds meer gebruik van machine learning.
De twee grootste verkopers van advertenties in de hele geschiedenis hoef je niet te overtuigen van het nut van machine learning. In 2018 meldde een wervingsbureau dat “80 procent van de ingenieurs op het gebied van machine learning met een doctorstitel door Google en Facebook zijn binnengehaald.”
De integriteit van AI-systemen is essentieel voor bedrijven die tientallen miljarden dollars verdienen met het leveren van advertentie-impressies. En het is des te belangrijker omdat vijandelijke aanvallen kunnen worden gebruikt om reputaties te vernietigen, de wereldpolitiek te beïnvloeden en mogelijk zelfs om drones uit te schakelen.
Het probleem met het beveiligen van AI-modellen
Een nieuw onderzoek van het SHERPA-consortium, een door de EU gefinancierd project waar F-Secure zich in 2018 bij heeft aangesloten, verklaart waarom het zo moeilijk is om AI-modellen te beveiligen.
Zo staat in het rapport dat “het moeilijk is systemen te verdedigen tegen vijandelijke aanvallen op modellen voor machine learning, omdat er voor aanvallers ontzettend veel manieren zijn om modellen te dwingen tot het genereren van onjuiste output”. Dit verklaart waarom de meeste modellen die in de praktijk worden gebruikt, vandaag de dag worden getraind “zonder rekening te houden met mogelijke vijandelijke input”.
De modellen werken zoals verwacht met de verwachte input. Jammer genoeg is de omvang van onverwachte input… onverwacht. En daarbij komt dat de complexiteit van de modellen toeneemt, dus wordt het steeds moeilijker om modellen voor te bereiden aanvallen te weerstaan.
Deze taak is misschien wel complexer dan de eeuwige klus van het vaststellen van kwetsbaarheden in software. Dit houdt namelijk in “het identificeren van input die ervoor zorgt dat het model onjuiste resultaten genereert, zoals false positives, false negatives of onjuiste beleidsbeslissingen, en het vaststellen of er vertrouwelijke gegevens uit het model kunnen worden gehaald.”
In het rapport worden 6 methoden benoemd om het risico op AI-aanvallen te beperken.
1. Voorspel aanvallen met ‘vijandelijke training’
Deze methode raadt aan om aanvallen in de vorm van vijandelijke steekproeven te voorspellen en deze op te nemen in de dataset van het model, zodat het de aanvallen kan afwijzen.
“Helaas zijn er nog tal van andere vijandelijke inputs mogelijk om een model dat op deze manier is gecreëerd voor de gek te houden. Om die reden biedt ‘vijandelijke training’ zelf alleen veerkracht tegen de eenvoudigste manieren van aanvallen,” wordt in het rapport opgemerkt.
‘Vijandelijke training’ lijkt op data augmentation, dat bijvoorbeeld wordt gebruikt om AI-fotoherkenning of modellen voor beeldclassificatie te verbeteren. “Door het omkeren, bijsnijden en aanpassen van de helderheid van elke input en deze toe te voegen aan de trainingsset” wordt het model verbeterd.
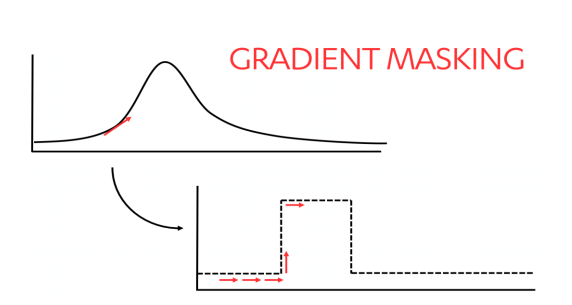
2. Breng aanvallers in de war met gradient masking
Aanvallers die een idee willen krijgen van hoe een model beslissingen neemt, kunnen meerdere inputs proberen in een poging een indruk te krijgen van het verloop in de resultaten. Op deze manier komen ze erachter hoe het model werkt, zodat ze het kunnen namaken en vijandelijke aanvallen ertegen kunnen oefenen.
“Gradient masking belemmert dit proces door scherpere grenzen te stellen voor beslissingen, zoals hieronder geïllustreerd…”
3. Bescherm je model door vijandelijke input te detecteren en te wissen
Een van de manieren om een model te beschermen, is door beveiligingen in te bouwen tussen het model en het publiek. Detection en cleaning kunnen de trucs van aanvallers verwijderen en ruwe gegevens rechtstreeks aan het model leveren.

Generative Adversarial Networks (GAN’s) helpen bij de detectie en het wissen van de input door twee verschillende modellen voor machine learning tegelijkertijd te trainen.
“Eén model, de generator, probeert voorbeelden (bijv. afbeeldingen) te genereren uit willekeurige ruis. Een tweede model, de discriminator, wordt gevoed met zowel echte voorbeelden als met de voorbeelden die door het generatormodel zijn gemaakt,” aldus het rapport. “De discriminator beslist welke voorbeelden echt en welke nep zijn. Naarmate de training vordert, wordt de generator er beter in om de discriminator voor de gek te houden, terwijl de discriminator beter wordt in het uitvogelen welke voorbeelden echt en nep zijn.”
4. Bescherm gebruikersgegevens met differential privacy
Differentiële privacy maakt gebruik van een algemene statistische techniek die voorkomt dat aanvallers de informatie in een statistische database blootleggen.
Een manier om dit te doen is door een reeks modellen te trainen tegen afzonderlijke, unieke onderdelen van de trainingsgegevens. Deze gegevens worden vervolgens in elk model ingevoerd samen met een kleine hoeveelheid willekeurige ruis. “De daaruit voortvloeiende waarden worden ‘votes’, waarvan de hoogste stem de output wordt.”
OpenMinded, een open-source gemeenschap, biedt gebruikers toegang tot het Syft-project, dat het mogelijk maakt om eenvoudig meerdere modellen te maken. Met deze modellen kunnen gebruikers gegevens beveiligen via verschillende methoden, waaronder differentiële privacy.
5. Behoud privacy voor de training en gevolgtrekking van modellen met behulp van crypto grafische technieken
Crypto grafische methoden zijn nuttig wanneer meerdere eigenaren van gegevens van elkaar afhankelijk zijn en elkaar niet per se vertrouwen. Het is zowel nuttig voor de gezamenlijke training van een model als voor wanneer een getraind model output genereert voor meerdere eigenaren van data.
In de afgelopen 50 jaar zijn er meerdere manieren ontwikkeld om gegevens te versleutelen, waarmee eigenaars tegelijkertijd hun data kunnen beveiligen en meer nut kunnen halen uit deze gegevens. Deze manieren kunnen afzonderlijk of in combinatie met elkaar worden gebruikt om de privacy van data te beschermen.
Deze technieken zijn echter slechts bruikbaar op een beperkt aantal algoritmes voor machine learning en vereisen soms een belastende hoeveelheid rekenkracht.
6. De menselijke geest is het tegengif tegen poisoning-aanvallen
Web diensten hebben gedurende deze eeuw te maken gehad met poisoning-aanvallen, waarbij de nodige verdediging is ontwikkeld om de reputatie van hun diensten te behouden.
De methoden die ze hebben bedacht vallen over het algemeen binnen vier categorieën: snelheidsbeperking, regressietesten, detectie van onregelmatigheden en menselijke tussenkomst.
Met snelheidsbeperkende strategieën wordt over het algemeen getracht vast te stellen of een gebruiker een mens is dat daadwerkelijk gebruikmaakt van een dienst of een gesimuleerd mens is dat is ontworpen om systemen te bespelen. Regressietesten voorkomen aanvallen door nieuwe modellen te testen aan de hand van basisnormen om onverwacht gedrag te detecteren. Methoden voor de detectie van onregelmatigheden kunnen verdacht gebruik ontdekken door metagegevens, waaronder IP-adressen, te analyseren met behulp van heuristisch onderzoek om abnormaal gebruik van de site te detecteren.
De meest effectieve methode om AI-misbruik te detecteren is echter nog niet afkomstig van een machine. Menselijke tussenkomst is nodig om regels te maken en om inhoud rechtstreeks te beperken.
De mens brengt menselijke vooroordelen met zich mee, die ingewikkelder zijn dan welk model ook.
“Zolang aanvallers echter menselijk zijn, zullen andere mensen net zo creatief moeten denken als de aanvallers om hun systemen tegen aanvallen te verdedigen,” wordt in het rapport opgemerkt. “Dit gegeven zal in de nabije toekomst niet veranderen.”
Wil je meer weten over dit onderwerp? Dat kan! Patrick praat je graag bij. Plan snel een afspraak met hem in.

Categorieën