6 modi per difendere l’intelligenza artificiale dagli esseri umani

Difendere l’intelligenza artificiale (IA) contro gli adversarial attacks diventa ogni giorno più importante poiché i servizi più popolari e affidabili al mondo si basano sempre più su modelli di apprendimento automatico.
I due maggiori venditori di pubblicità non hanno bisogno di essere convinti dell’utilità dell’apprendimento automatico. Nel 2018, una società di reclutamento ha riferito che “l’80% degli ingegneri con dottorati che si occupano di machine learning è assunto da Google e Facebook”.
L’integrità dei sistemi di intelligenza artificiale è essenziale per le aziende che producono decine di miliardi di dollari rilasciando impression pubblicitarie. Ed è ancora più vitale in quanto gli adversarial attacks potrebbero essere usati per distruggere reputazioni, influenzare la politica globale e persino abbattere droni.
Il problema con la protezione dei modelli di intelligenza artificiale
“Security Issues, Dangers and Implications of Smart Information Systems”, il nuovo studio pubblicato dal consorzio SHERPA – un progetto finanziato dall’UE a cui F-Secure ha aderito nel 2018 – spiega perché è così difficile proteggere i modelli di intelligenza artificiale.
“Gli adversarial attacks contro i modelli di apprendimento automatico sono difficili da difendere perché ci sono molti modi in cui gli attaccanti possono forzare i modelli per produrre output errati”, si dice nella Sezione 4 su “Mitigations against adversarial attacks”. Questo aiuta a spiegare perché la maggior parte dei modelli “in natura” oggi vengono addestrati “indipendentemente da possibili input adversarial”.
I modelli funzionano come previsto con gli input previsti. Sfortunatamente, il numero di input inaspettati è … inaspettato. E con l’aumentare della complessità dei modelli, la preparazione di modelli per resistere agli attacchi diventa sempre più difficile.
Questo compito può essere persino più complesso del compito infinito di identificare le vulnerabilità nel software perché “implica l’identificazione di input che inducono il modello a produrre verdetti errati, come falsi positivi, falsi negativi o decisioni politiche sbagliate, e identificare se dati confidenziali possono essere estratti dal modello.”
Il rapporto identifica 6 metodi per mitigare gli attacchi contro l’intelligenza artificiale.
Anticipa gli attacchi con una formazione sugli adversarial
Questo metodo suggerisce di anticipare gli attacchi nella forma di adversarial attacks e di includerli nel set di dati del modello da rifiutare.
“Sfortunatamente, ci sono molti altri campioni di adversarial attacks che possono essere creati che imbrogliano un modello creato in questo modo, e quindi l’addestramento sull’adversarial stesso fornisce resilienza solo con i metodi di attacco più semplici”, osserva il rapporto.
La formazione sull’adversarial assomiglia all’aumento dei dati, che viene utilizzato, ad esempio, per migliorare il riconoscimento delle foto con IA o i modelli di classificazione delle immagini. “Capovolgendo, ritagliando e regolando la luminosità di ciascun campione di input e aggiungendoli al set di addestramento” il modello migliora.
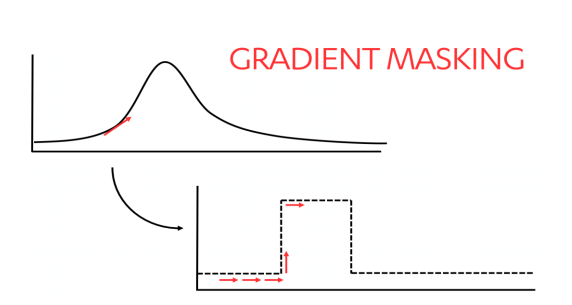
Confondere gli attaccanti con il gradient masking
Gli attaccanti che cercano di capire come un modello prende le decisioni possono provare più input nel tentativo di ottenere un senso del gradient nei risultati. Questo li aiuta a comprendere come funziona il modello in modo da poterlo replicare e praticare attacchi adversarial contro di esso.
“Il gradient masking ostacola questo processo creando limiti di decisione più nitidi, come illustrato di seguito …”
Proteggi il tuo modello rilevando e pulendo gli input adversarial
Un modo per proteggere il tuo modello è mettere delle garanzie tra esso e il pubblico. Il rilevamento e la pulizia possono rimuovere i trucchi degli attaccanti e fornire dati grezzi direttamente al modello.

Generative Adversarial Networks (GAN) aiutano a rilevare e pulire gli input addestrando due diversi modelli di apprendimento automatico allo stesso tempo.
“Un modello, il generatore, tenta di generare campioni (ad esempio immagini) dal rumore casuale. Un secondo modello, il discriminatore, viene alimentato sia con campioni reali sia con i campioni creati dal modello generatore”, osserva il rapporto. “Il discriminatore decide quali campioni sono reali e quali sono falsi. Man mano che l’addestramento procede, il generatore migliora nell’ingannare il discriminatore, mentre il discriminatore migliora nel capire quali campioni sono reali o falsi. ”
Salvaguarda i dati degli utenti con la privacy differenziale
La privacy differenziale utilizza una tecnica statistica generale per impedire agli attaccanti di esporre le informazioni in un database statistico.
Un metodo per farlo richiede l’addestramento di una serie di modelli contro porzioni separate e uniche di dati di addestramento. I dati vengono quindi immessi in ciascun modello con una piccola quantità di rumore casuale. “I valori risultanti diventano” voti “, il più alto dei quali diventa l’output”.
OpenMinded—una community open-source—offer accesso agli utenti al progetto Syft che consente la creazione semplificata di più modelli per proteggere i dati tramite vari metodi, inclusa la privacy differenziale.
Preserva la privacy per l’addestramento e l’inferenza del modello usando tecniche crittografiche
I metodi crittografici sono utili quando più proprietari di dati devono fare affidamento su ciascuno di essi e non si fidano necessariamente l’uno dell’altro. È utile sia per l’addestramento collaborativo di un modello sia quando un modello addestrato produce risultati per più proprietari di dati.
Negli ultimi cinquant’anni sono stati sviluppati diversi modi di crittografare i dati per fornire ai proprietari un modo per proteggere i loro dati ottenendo al contempo più utilità da essi, che possono essere utilizzati da soli o in combinazione per proteggere la privacy dei dati.
Tuttavia, queste tecniche sono utili solo su un numero limitato di algoritmi di apprendimento automatico e possono richiedere una notevole quantità di potenza di calcolo.
La mente umana è l’antidoto ai poisoning attack
I servizi Web hanno affrontato poisoning attacks nel corso di questo secolo, sviluppando le difese necessarie per preservare la reputazione dei loro servizi.
I metodi che hanno escogitato rientrano generalmente in quattro categorie: limitazione della frequenza, test di regressione, rilevazione di anomalie e intervento umano.
Le strategie di limitazione della velocità generalmente cercano di determinare se un utente è un essere umano che utilizza realmente un servizio o un uso umano simulato progettato per giocare con i sistemi. I test di regressione prevengono gli attacchi testando nuovi modelli rispetto agli standard di base per rilevare comportamenti imprevisti. I metodi di rilevamento delle anomalie possono trovare un uso sospetto analizzando i metadati inclusi i destinatari IP utilizzando l’analisi euristica per rilevare un uso anomalo del sito.
Ma il metodo più efficace per rilevare l’abuso dell’IA non proviene ancora da una macchina: è necessario un intervento umano per creare regole e moderare il contenuto.
Gli esseri umani portano pregiudizi umani, che sono più complicati di qualsiasi modello.
“Tuttavia, finché gli aggressori sono umani, ci vorranno altri umani per pensare in modo creativo come gli attaccanti al fine di difendere i sistemi dagli attacchi”, osserva il rapporto. “Questo fatto non cambierà nel prossimo futuro.”
Categorie